Vault
Secure external data with Vault
Not all personally identifiable information (PII) lives in Vault. For example, you may need to store credit card numbers, patient IDs, or social security numbers in an external databases.
It can be difficult to secure sensitive data outside Vault and balance the need for applications to access the data efficiently while adhering to stringent security standards and protocols. Vault helps you secure external data with transit encryption, tokenization, and transforms.
Transform consists of three modes, called transformations. Format Preserving Encryption (FPE) for encrypting and decrypting values while retaining their formats. Masking for replacing sensitive information with masking characters. And Tokenization which replaces sensitive information with mathematically unrelated tokens.
Encrypt sensitive data with Vault transit
Encrypting sensitive data is an obvious solution for protecting sensitive data. But independently implementing robust data encryption can be complex and expensive. The Vault transit plugin encrypts data, returns the resulting ciphertext, and manages the associated encryption keys. Your application only ever persists the ciphertext and never deals directly with the encryption key.
For example, the following diagram shows a credit card number going into the transit system and returning to persistent storage as encrypted data.
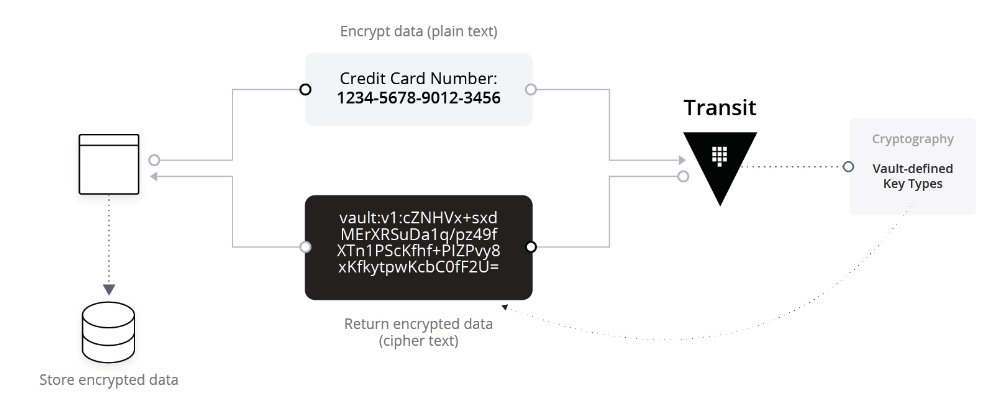
The tradeoff with encryption is that the ciphertext is often much longer than the original data. Additionally, the ciphertext can contain characters that are not allowed in the original data, which may cause your system to reject the encrypted data. As a result, you may modify your database schema or adjust your data validation system to avoid rejecting the encrypted data.
Tokenize sensitive data
Tokenization safeguards sensitive information by randomly generating a token with a one-way cryptographic hash function. Rather than storing the data directly, the system saves the token to persistent storage and maintains a mapping between the original data and the token.
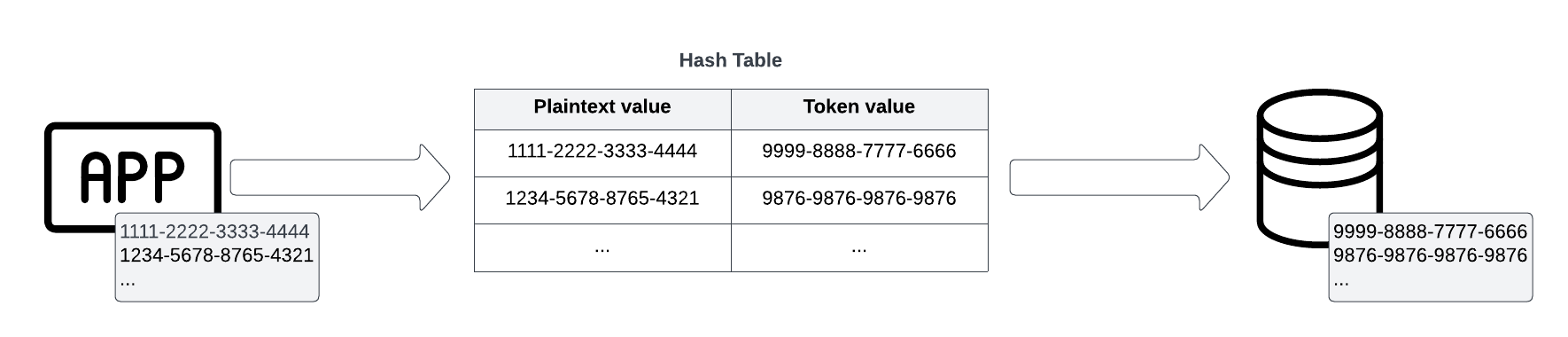
Combining effective tokenization and a robust random number generator ensures protected data security regardless of where the data lives. However, even if tokenization hides the format of the data, it can be a leaky abstraction if the final token ends up the same length of the original data. Additionally, when the token length matches the original length, format checkers may not realize the data is tokenized and could reject the tokenized value as "invalid data".
Tokenization also presents scalability challenges because the hash table expands any time the system stores a new tokenized value. A rapidly expanding hash table affects storage and performance as the speed of hash searches declines.
Maintaining cryptographic data security with tokenization is a complex task that requires protection of the tokenized data and the hash table to ensure data integrity and security.
Obscure sensitive data with Vault transform
Enterprise
The Vault transform plugin requires a Vault Enterprise license with Advanced Data Protection (ADP).
We recommend using the Vault transform plugin for securing external, sensitive data with Vault. The transform plugin supports three transformations:
- format preserving encryption
- data masking
- tokenization
In addition to providing the option of data masking, Vault transform simplifies some of the complexities with stand-alone encryption and tokenization.
Format preserving encryption
Format preserving encryption (FPE) is a two-way transformation that encrypts external data while maintaining the original format and length. For example, transforming a credit card number to an encoded ciphertext made of 16 numbers.
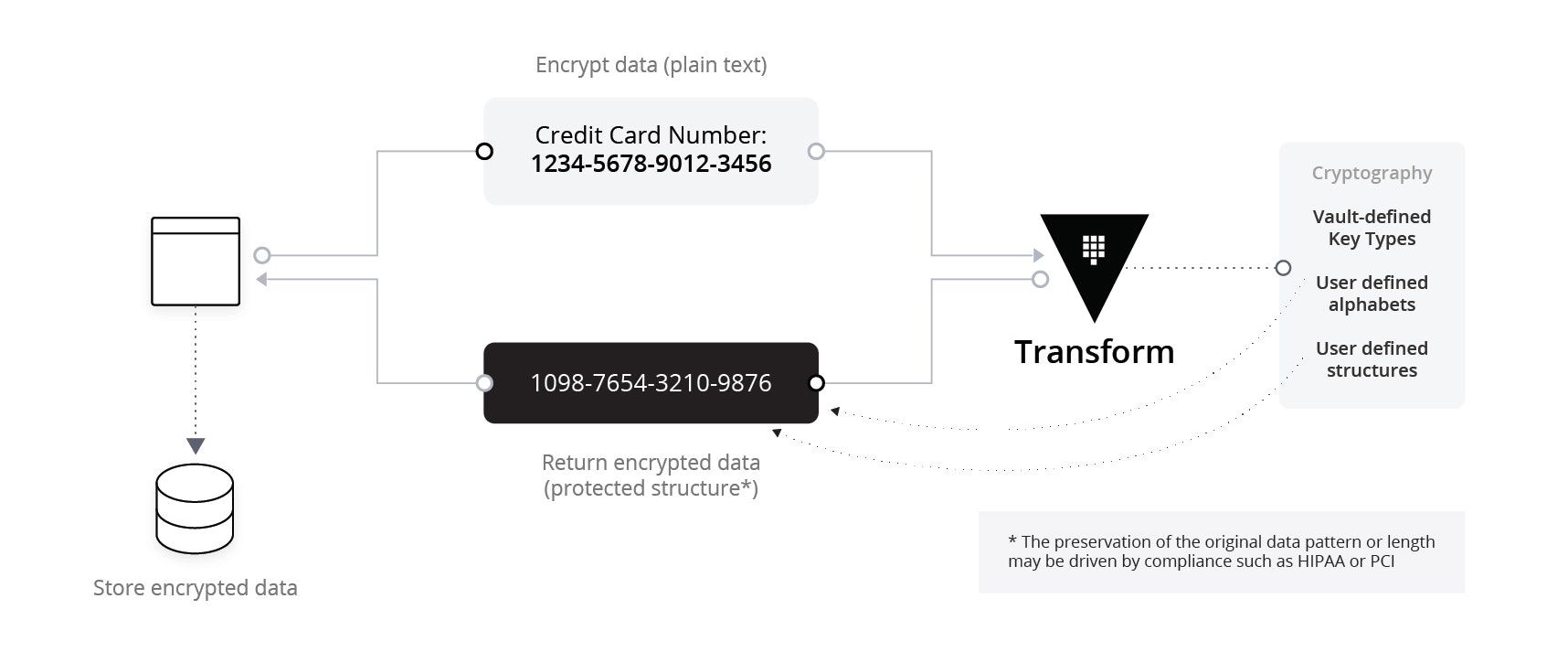
Unlike stand-alone encryption, FPE maintains the original length and data structure for encoded data so the transformed data works with your existing database schema and validation systems. And, unlike tokenization, FPE preserves the original structure without the risk of leaky abstraction.
FPE is secure
Vault uses the FF3-1 algorithm to ensure the security of the encoded ciphertexts. The National Institute of Standards and Technology (NIST) vets, updates, and tests the FF3-1 algorithm to protect against specific types of attacks and potential future threats from supercomputers.
In addition to providing built-in transformation templates for common data like credit card numbers and US social security numbers, format preserving encryptions support custom transformation templates. You can use regular expressions to specify the values you want to transform and enforce a schema on the encoded value.
FPE transformation is also stateless, which means that Vault does not store the protected secret. Instead, Vault protects the encryption key needed to decrypt the ciphertext. By only storing the information needed to decrypt the ciphertext, Vault provides maximum performance for encoding and decoding operations while also minimizing exposure risk for the data.
Data masking
Data masking is a one-way transformation that replaces characters on the input value with a predefined translation character.
Use with caution
Masking is non-reversible. We do not recommend masking for situations where you need to retrieve and decode the original value.
Data masking is a good solution when you need to show or print sensitive data without full readability. For example, masking a a bank account number in an online banking portal to prevent potential security breaches from bad actors who might be observing the screen.
Tokenization
Unlike standalone tokenization, tokenization with Vault transform is a two-way, random encoding that satisfies the PCI-DSS requirement for data irreversibility while still allowing you to decode tokens back to their original plaintext.
To support token decoding, Vault secures a cryptographic mapping of tokens and plaintext values in internal storage. Even if an attacker steals the underlying transformation key and mapping values from Vault, tokenization of the data prevents the attacker from recovering the original plaintext.
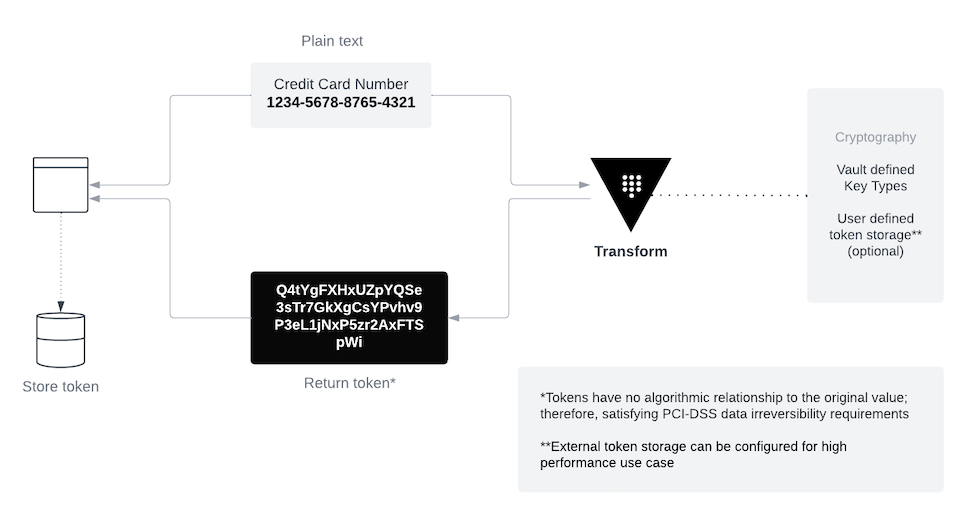
Vault transform creates a new key for each tokenization transformation, which helps ensure a strong cryptographic distinction between different tokenization use cases. For example, a credit card processor may want to distinguish between the same credit card number used by different merchants without having to decode the token.
Tokenization transform also supports automatic key rotation based on a configurable time interval and minimum key version. Each configured tokenization transformation keeps a set of versioned keys. When a key rotates, older key versions, within the configured age limit, are still available for decoding tokens generated in the past. Vault cannot decode generated tokens with keys below the minimum key version.
Convergent tokenization
By default, tokenization produces a unique token for every encode operation. Vault transform supports convergent tokenization, which lets you use the same encoded value for a given input.
Convergent tokenization lets you perform statistical analysis of the tokens in your system without decoding the token. For example, counting the entries for a given token, querying relationships between a token and other fields in your database, and relating information that is tokenized across multiple systems.
Performance considerations with Vault transform
Tokenization transformation is stateful, which means the encode operation must perform writes to storage on the primary node of your Vault cluster. As a result, any storage performance limits on the primary node also limits scalability of the encode operation.
In comparison, neither Vault transit encryption nor FPE transformation write to storage, and both can be horizontally scaled using performance standby nodes.
For high-performance use cases, we recommend that you configure Vault to store the token mapping in an external database. External stores can achieve a much higher performance scale and reduce the load on the internal storage for your Vault installation.
Vault currently supports the following external storage systems:
- PostgreSQL
- MySQL
- MSSQL.
For more information on external storage, review the Tokenization transform storage documentation.